My Cloud Resume Challenge

I loveee Linux & the command line! I could sell my birthright for some cake I watch movies, eat, play music & day-dream in my spare time
I finally implemented my version of the now infamous ‘Cloud Resume Challenge’ by Forrest Brazeal. From my very early days on my cloud journey, I have looked forward to tackling this project and i am glad to say that I have finally accomplished this little goal. I have read blogposts by others like me who have undertaken the challenge, and one thing that remained consistent was the fact that this is a highly rewarding, albeit challenging project to undertake as a beginner. Just like everyone else, the cloud resume challenge took me down several rabbit holes of research and learning, for which i am grateful for.
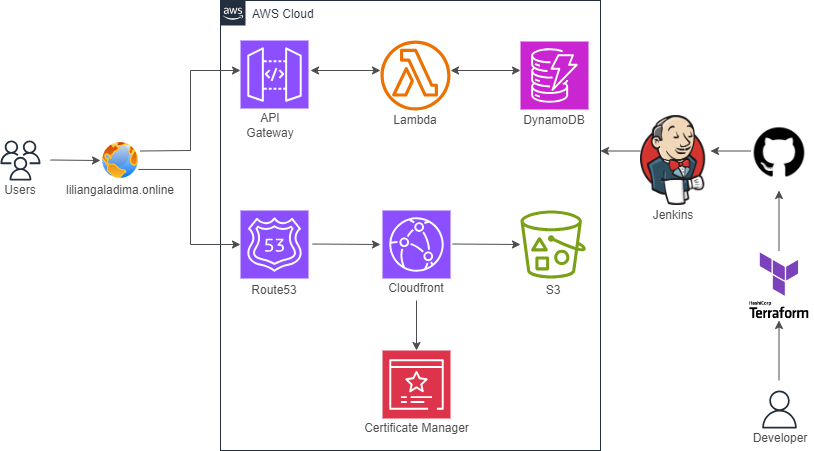
I wouldn’t like to bore with all the specifics and technicalities of my journey but if you’re here and searching for some guidance from others who have documented their sojourn of the CRC: AWS version, I suggest these posts by Rishab Kumar and Omar Butt. There are much more out there and a simple Google search will lead to countless others.
The one thing I would want to document though, is an issue that had me tearing my hair strands out. I didn’t come across any detailed posts concerning this but I eventually overcame the hurdle thanks to a huge amount of Googling time, plus the ever helpful StackOverflow. This setback had to do AWS S3 and how it handles objects’ files.
When you upload objects to S3 using the Management console, S3 automatically recognizes file types using their file extensions. For example, if you upload a JavaScript file named script.js, S3 recognizes that this is indeed a JavaScript file thanks to the .js extension. Same applies to other file types. S3 also automatically assigns these respective file types in the files’ metadata. This allows it to save/render your files accordingly and correctly.
With Terraform however, this is not the case. When you define your resources in terraform, S3 CANNOT auto-assign these file types. While provisioning your code, you must manually tell S3 what type of file each is. This is actually fairly easy, until you have a myriad of files with differing types. A good example (as it were in my case) is hosting a site containing different file types: HTML, CSS, Javascript, JPG & PNG files all within one directory that hosts a web app’s files. Because I wasn’t aware of S3’s inability to auto manage these file types, I was left confused as to why my app wasn’t rendered correctly after applying my code. CSS and Javascript were not rendered at all. After a significant amount of research, I discovered why this happened and sought to find a solution. After a while, I finally found a way to tell Terraform how to dynamically assign file types to each file in my directory. The screenshot below is a snippet from my terraform code that shows this solution.
locals {
content_type_map = {
"js" = "application/javascript"
"html" = "text/html"
"css" = "text/css"
"png" = "image/png"
"jpg" = "image/jpeg"
}
}
resource "aws_s3_object" "site" {
bucket = aws_s3_bucket.website_bucket.bucket
for_each = fileset("./site_files/", "**/*")
key = each.value
source = "./site_files/${each.value}"
content_type = lookup(local.content_type_map, split(".", "${each.value}")[1], "text/html")
etag = filemd5("./site_files/${each.value}")
}
Aaannnd after many hours of pain and agony, it finally worked! Pheww! You can find the rest of my code in this repository.
I hope this helps someone out there. Happy learning!



